
This post has moved to eklausmeier.goip.de/blog/2021/02-01-performance-comparison-ryzen-vs-intel-vs-bulldozer-vs-arm.
For comparing different machines I invert the Hilbert matrix

This matrix is known have very high condition numbers. Program xlu5.c stores four double precision matrices of dimension 
H and A store the Hilbert matrix, X is the identity matrix, Y is the inverse of H. Finally the maximum norm of 
1. Runtime on Ryzen, AMD Ryzen 5 PRO 3400G with Radeon Vega Graphics, max 3.7 GHz, as given by lscpu.
$ time xlu5o3b 230 > /dev/null
real 0.79s
user 0.79s
sys 0
swapped 0
total space 0
Cache sizes within CPU are:
L1d cache: 128 KiB L1i cache: 256 KiB L2 cache: 2 MiB L3 cache: 4 MiB
Required storage for above program is 4 matrices, each having 230×230 entries with double (8 bytes), giving 1692800 bytes, roughly 1.6 MB.
2. Runtime on AMD FX-8120, Bulldozer, max 3.1 GHz, as given by lscpu.
$ time xlu5o3b 230 >/dev/null
real 1.75s
user 1.74s
sys 0
swapped 0
total space 0
Cache sizes within CPU are:
L1d cache: 64 KiB L1i cache: 256 KiB L2 cache: 8 MiB L3 cache: 8 MiB
3. Runtime on Intel, Intel(R) Core(TM) i5-4250U CPU @ 1.30GHz, max 2.6 GHz, as given by lscpu.
$ time xlu5o3b 230 > /dev/null
real 1.68s
user 1.67s
sys 0
swapped 0
total space 0
Cache sizes within CPU are:
L1d cache: 64 KiB L1i cache: 64 KiB L2 cache: 512 KiB L3 cache: 3 MiB
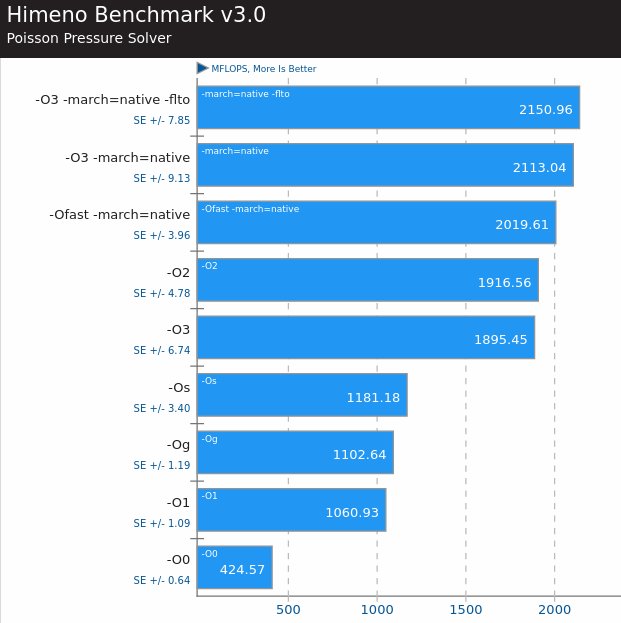
Apparently the Ryzen processor can outperform the Intel processor on cache, higher clock frequency. But even for smaller matrix sizes, e.g., 120, the Ryzen is two times faster.
Interestingly, the error in computations are different!
AMD and Intel machines run ArchLinux with kernel version 5.9.13, gcc was 10.2.0.
4. Runtime on Raspberry Pi 4, ARM Cortex-A72, max 1.5 GHz, as given by lscpu.
$ time xlu5 230 > /dev/null
real 4.37s
user 4.36s
sys 0
swapped 0
total space 0
Linux 5.4.83 and GCC 10.2.0.
5. Runtime on Odroid XU4, Cortex-A7, max 2 GHz, as given by lscpu.
$ time xlu5 230 > /dev/null
real 17.75s
user 17.60s
sys 0
swapped 0
total space 0
So the Raspberry Pi 4 is clearly way faster than the Odroid XU4.






You must be logged in to post a comment.