
This post has moved to eklausmeier.goip.de/blog/2021/03-29-php-extension-seg-faulting.
Task at hand: Call Cobol (=GnuCobol) from PHP. I used FFI for this:
<?php
$cbl = FFI::cdef("int phpsqrt(void); void cob_init_nomain(int,char**); int cob_tidy(void);", "/srv/http/phpsqrt.so");
$ffj0 = FFI::cdef("double j0(double);", "libm.so.6");
$cbl->cob_init_nomain(0,null);
$ret = $cbl->phpsqrt();
printf("\tret = %d<br>\n",$ret);
echo "Before calling cob_tidy():<br>\n";
echo "\tReturn: ", $cbl->cob_tidy(), "<br>\n";
printf("j0(2) = %f<br>\n", $ffj0->j0(2));
?>
The Cobol program is:
000010 IDENTIFICATION DIVISION. 000020 PROGRAM-ID. phpsqrt. 000030 AUTHOR. Elmar Klausmeier. 000040 DATE-WRITTEN. 01-Jul-2004. 000050 000060 DATA DIVISION. 000070 WORKING-STORAGE SECTION. 000080 01 i PIC 9(5). 000090 01 s usage comp-2. 000100 000110 PROCEDURE DIVISION. 000120* DISPLAY "Hello World!". 000130 PERFORM VARYING i FROM 1 BY 1 UNTIL i > 10 000140 move function sqrt(i) to s 000150* DISPLAY i, " ", s 000160 END-PERFORM. 000170 000180 move 17 to return-code. 000190 GOBACK. 000200
Config in php.ini file has to be changed:
extension=ffi ffi.enable=true
To call GnuCobol from C, you have to first call cob_init() or cob_init_nomain(), which initializes GnuCobol. I tried both initialization routines, and both resulted in PHP crashing after running above program, i.e., segmentation fault.
I created a bug for this: FFI crashes with segmentation fault when calling cob_init().
1. I compiled PHP 8.0.3 from source. For this I had to add below packages:
pacman -S tidy freetds c-client
I grep’ed my current configuration:
php -i | grep "Configure Comman" Configure Command => './configure' '--srcdir=../php-8.0.3' '--config-cache' '--prefix=/usr' '--sbindir=/usr/bin' '--sysconfdir=/etc/php' '--localstatedir=/var' '--with-layout=GNU' '--with-config-file-path=/etc/php' '--with-config-file-scan-dir=/etc/php/conf.d' '--disable-rpath' '--mandir=/usr/share/man' '--enable-cgi' '--enable-fpm' '--with-fpm-systemd' '--with-fpm-acl' '--with-fpm-user=http' '--with-fpm-group=http' '--enable-embed=shared' '--enable-bcmath=shared' '--enable-calendar=shared' '--enable-dba=shared' '--enable-exif=shared' '--enable-ftp=shared' '--enable-gd=shared' '--enable-intl=shared' '--enable-mbstring' '--enable-pcntl' '--enable-shmop=shared' '--enable-soap=shared' '--enable-sockets=shared' '--enable-sysvmsg=shared' '--enable-sysvsem=shared' '--enable-sysvshm=shared' '--with-bz2=shared' '--with-curl=shared' '--with-db4=/usr' '--with-enchant=shared' '--with-external-gd' '--with-external-pcre' '--with-ffi=shared' '--with-gdbm' '--with-gettext=shared' '--with-gmp=shared' '--with-iconv=shared' '--with-imap-ssl' '--with-imap=shared' '--with-kerberos' '--with-ldap=shared' '--with-ldap-sasl' '--with-mhash' '--with-mysql-sock=/run/mysqld/mysqld.sock' '--with-mysqli=shared,mysqlnd' '--with-openssl' '--with-password-argon2' '--with-pdo-dblib=shared,/usr' '--with-pdo-mysql=shared,mysqlnd' '--with-pdo-odbc=shared,unixODBC,/usr' '--with-pdo-pgsql=shared' '--with-pdo-sqlite=shared' '--with-pgsql=shared' '--with-pspell=shared' '--with-readline' '--with-snmp=shared' '--with-sodium=shared' '--with-sqlite3=shared' '--with-tidy=shared' '--with-unixODBC=shared' '--with-xsl=shared' '--with-zip=shared' '--with-zlib'
To this I added --enable-debug. Command configure needs two minutes. Then make -j8 needs another two minutes.
I copied php.ini to local directory, changed it to activated FFI. Whenever I called
$BUILD/sapi/cli/php
I had to add -c php.ini, when I called an extension written by me, stored in ext/.
2. The fix for segmentation fault is actually pretty easy: Just set environment variable ZEND_DONT_UNLOAD_MODULES:
ZEND_DONT_UNLOAD_MODULES=1 $BUILD/sapi/cli/php -c php.ini -r 'test1();'
Reason for this: see valgrind output below.
3. Before I had figured out the “trick” with ZEND_DONT_UNLOAD_MODULES, I wrote a PHP extension. The extension is:
/* {{{ void test1() */
PHP_FUNCTION(test1)
{
ZEND_PARSE_PARAMETERS_NONE();
php_printf("test1(): The extension %s is loaded and working!\r\n", "callcob");
cob_init(0,NULL);
}
/* }}} */
Unfortunately, running this extension resulted in:
Module compiled with build ID=API20200930,NTS PHP compiled with build ID=API20200930,NTS,debug These options need to match
I solved this by adding below string:
/* {{{ callcob_module_entry */
zend_module_entry callcob_module_entry = {
STANDARD_MODULE_HEADER,
//sizeof(zend_module_entry), ZEND_MODULE_API_NO, 1, USING_ZTS,
"callcob", /* Extension name */
ext_functions, /* zend_function_entry */
NULL, /* PHP_MINIT - Module initialization */
NULL, /* PHP_MSHUTDOWN - Module shutdown */
PHP_RINIT(callcob), /* PHP_RINIT - Request initialization */
NULL, /* PHP_RSHUTDOWN - Request shutdown */
PHP_MINFO(callcob), /* PHP_MINFO - Module info */
PHP_CALLCOB_VERSION, /* Version */
STANDARD_MODULE_PROPERTIES
",debug"
};
/* }}} */
I guess this is not the recommend approach.
4. Valgrind shows the following:
==37350== Process terminating with default action of signal 11 (SIGSEGV): dumping core ==37350== Access not within mapped region at address 0x852AD20 ==37350== at 0x852AD20: ??? ==37350== by 0x556EF7F: ??? (in /usr/lib/libc-2.33.so) ==37350== by 0x5570DCC: getenv (in /usr/lib/libc-2.33.so) ==37350== by 0x76BB43: module_destructor (zend_API.c:2629) ==37350== by 0x75EE31: module_destructor_zval (zend.c:782) ==37350== by 0x7777A1: _zend_hash_del_el_ex (zend_hash.c:1330) ==37350== by 0x777880: _zend_hash_del_el (zend_hash.c:1353) ==37350== by 0x779188: zend_hash_graceful_reverse_destroy (zend_hash.c:1807) ==37350== by 0x769390: zend_destroy_modules (zend_API.c:1992) ==37350== by 0x75F582: zend_shutdown (zend.c:1078) ==37350== by 0x6C3F17: php_module_shutdown (main.c:2359) ==37350== by 0x84E46D: main (php_cli.c:1351) ==37350== If you believe this happened as a result of a stack ==37350== overflow in your program's main thread (unlikely but ==37350== possible), you can try to increase the size of the ==37350== main thread stack using the --main-stacksize= flag. ==37350== The main thread stack size used in this run was 8388608. . . . zsh: segmentation fault (core dumped) valgrind $BUILD/sapi/cli/php -c $BUILD/php.ini -r 'test1();'
As shown above, the relevant code in question is Zend/zend_API.c in line 2629. This is shown below:
void module_destructor(zend_module_entry *module) /* {{{ */
{
. . .
module->module_started=0;
if (module->type == MODULE_TEMPORARY && module->functions) {
zend_unregister_functions(module->functions, -1, NULL);
}
#if HAVE_LIBDL
if (module->handle && !getenv("ZEND_DONT_UNLOAD_MODULES")) {
DL_UNLOAD(module->handle);
}
#endif
}
/* }}} */
It is the DL_UNLOAD, which is a #define for dlclose, which actually provokes the crash.
According PHP Internals Book — Zend Extensions:
Here, we are loaded as a PHP extension. Look at the hooks. When hitting MSHUTDOWN(), the engine runs our MSHUTDOWN(), but it unloads us just after that ! It calls for dlclose() on our extension, look at the source code, the solution is as often located in there.
So what happens is easy, just after triggering our RSHUTDOWN(), the engine unloads our pib.so ; when it comes to call our Zend extension part shutdown(), we are not part of the process address space anymore, thus we badly crash the entire PHP process.
What is still not understood: Why does FFI not crash with those simple functions, like printf(), or sqrt()?

 . Matrix
. Matrix  is printed, which should be zero. These four double precision matrices occupy roughly 1.6 MB for
is printed, which should be zero. These four double precision matrices occupy roughly 1.6 MB for 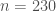 .
.





You must be logged in to post a comment.